
Asynchronous Python
Concurrency, Threads, and the Global Interpreter Lock Await You
In this essay, we discuss a few different models of concurrency and how they are implemented in Python. Additionally, we address the shortcomings and advantages of each as well as dispel some myths about performance. There are also a few code samples within a sample command line interface to demonstrate the concepts illustrated here.
Source Code
Check out the async python demo repo here to play around with tasks, queues, httpx, and the MLB stats API.
Overview
Asynchronous programming is the process of writing code that includes events that occur independently of the main flow of the program. So a process will begin, but the interpreter will continue to execute the next steps of the program. This allows us to do multiple things at the same time. In contrast, synchronous code is executed sequentially, or a single step at a time. Each statement is executed and the computation completed before moving on to the next. It is often easy to think of the functions that are being executed like an algebraic function, in which each operation/computation occurs in a predictable order. In other words, if we imagine each operation as a task, they are performed one at a time, with one finishing completely before another the next. If they're always performed in the same order, the implementation of later tasks can assume that previous tasks finished error-free.
Multi-Threaded Model
Another model for task execution, is the multi-threaded model. each task is performed in a separate thread of control, managed by the operating system kernel. On systems with multiple processors or multiple cores, run truly concurrently. This is commonly referred to as preemptive multitasking.1
Cooperative Multitasking & GIL
In the async model, tasks execution order is interleaved with one another in a single thread. This is simpler than the threaded case because the programmer always knows that when one task is executing, another task is not. It is called cooperative multitasking. We'll discuss the implications of that later. For now, know that this makes an async thread subject to the Global Interpreter Lock (GIL). This is a mutex that ensures that there are no race conditions2. The work around for that to create multiple threads is a multithreading library.
Asynchronous programming is relevant for processes/tasks dependent on computer resources outside the CPU. For example, HTTP resources require accessing the network and opening and closing files require disk access. Synchronous statements calls are called blocking (blocking calls), because they must be executed before the next statement runs.3
Demo
Here are some simple examples that ostensibly do the same things. We create a queue (remember, FIFO - first in first out), that contains tasks (simple operations), and then we iterate through the queue and execute the tasks. I've wrapped these in a simple click CLI. See the README in the associated repo for instructions on installation.
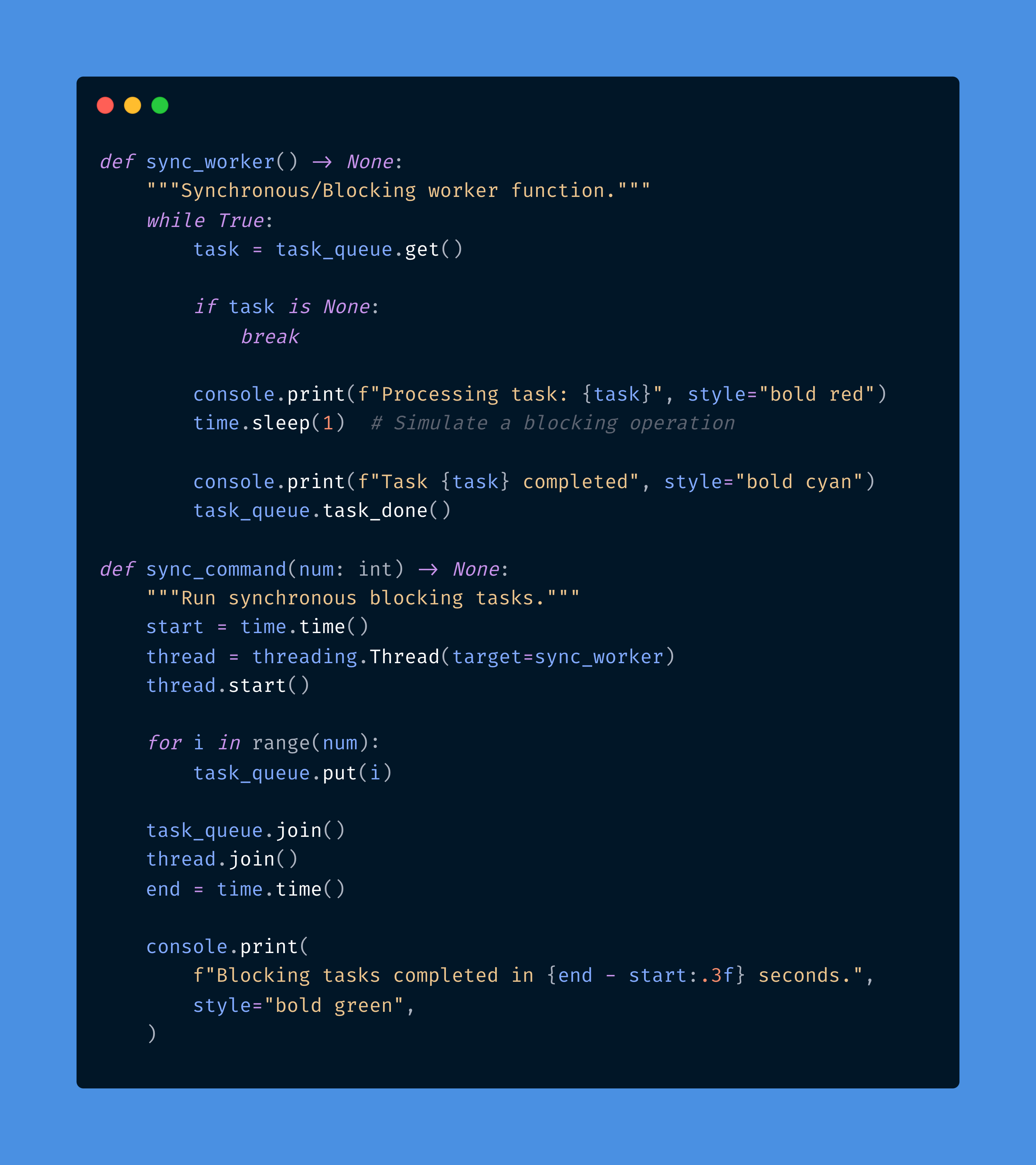
In the sync function, we create a queue and run a blocking worker function that processes tasks from the queue. We do this by using the standard library threading module and queue module, where each task is a simple pause using time.sleep(1) to simulate a blocking operation. This demonstrates how a blocking worker running in a single thread processes tasks sequentially.
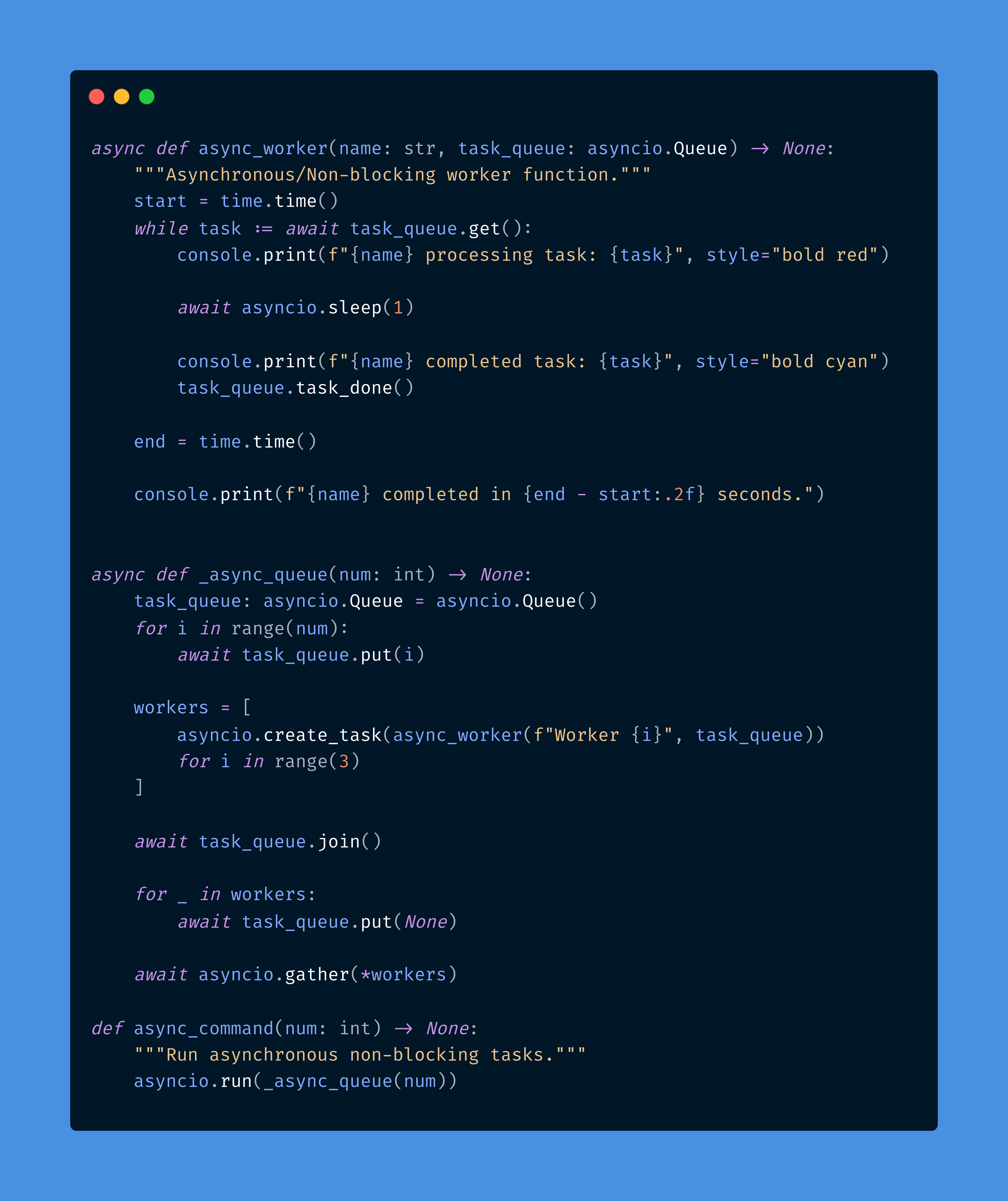
In the async function, we create an asyncio queue and run a non-blocking worker function that processes tasks from the queue. In this case, we have two workers running concurrently, processing tasks from the queue. We're using a single-threaded event loop to run the workers concurrently. This demonstrates how non-blocking workers can run concurrently in a single thread while using the asyncio module. asyncio's sleep function is used to simulate the time it may take to complete an operation like I/O-bound tasks or network requests. This is referred to as cooperative multitasking4, where the event loop continues execution while the task waits for whatever resource it needs. Another example of this is done via python generators, which use yield (the task yields control to the loop).
HTTP Requests
HTTPx is a library that gives us both an async and synchronous interface. This can provide us with a good way to demonstrate the differences between two ways to write concurrent code when the tasks are not CPU-bound. Usually you'll see simple synchronous requests in python code executed by the requests package. The key differences in the synchronous case are the extensibility of the httpx Client object, and support for http/2. In the demo application (see cli/http.py), you can compare the time to synchronously fetch the JSON data for all 30 MLB teams versus running the tasks concurrently using the AsyncClient class from httpx.
HTTP/1.1 vs HTTP/2
The differences between http/1.1 and http/2, which come down to four major points: content prioritization, multiplexing, server push, and header compression5. Multiplexing does a lot to enhance the efficiency for developers, as it is a feature allow for a single tcp connection to be maintained between the server and client, where the client opens up multiple streams to fetch data. Server push lets the server send data to the client after sending a message detailing what content is coming. Header compression compresses redundant http header information using HPACK. When multiple requests are made, the small decreases in packet size can add up to decrease latency. Content prioritization on the other hand has more to do with web pages, as it allows the client to choose which content is loaded first (between static files like CSS or JavaScript).
Which Concurrency Model Wins?
A common myth is that async python code is faster than synchronous due to concurrency. As mentioned previously, this is cooperative multitasking in a single thread. Because it is cooperative, threads don't have CPU distributed evenly, as execution has to be relinquished by the task itself instead of interrupted by a governor like the operating system kernel. Cal Peterson demonstrates this when benchmarking synchronous and asynchronous servers6 He notes that async servers don't need as many workers because they can use a single CPU. It's the latency caused by the yielding of a task that slows them down. He notes that throughput is determined by the amount of python replaced by native code.
Further Reading
1. Async Python from Hackernoon (link)
2. 500 Lines or Less: A Web Crawler with Asyncio Coroutines (link)
3. Structured Concurrency, used by an alternative to asyncio, Trio. The pattern here is called the "nursery pattern," in which threads have clear entry and exit points and are encapsulated in constructs called nurseries. These ensure that the execution of the thread has completed before the process exits.7
Images of code from carbon.
Fonseca, R. (2012). Async Programming [Class handout]. Brown University, CSCI 1680.
“The Python GIL (Global Interpreter Lock) • Python Land Tutorial.” _Python Land_, 18 Dec. 2021, https://python.land/python-concurrency/the-python-gil.
Grinberg, Miguel. Sync vs. Async Python: What Is the Difference? https://blog.miguelgrinberg.com/post/sync-vs-async-python-what-is-the-difference. Accessed 24 Nov. 2024.
“Cooperative Multitasking.” Wikipedia, 31 Jan. 2024. Wikipedia, https://en.wikipedia.org/w/index.php?title=Cooperative_multitasking&oldid=1201426758.
“HTTP/2 vs. HTTP/1.1.” Cloudflare.com, 2015, www.cloudflare.com/learning/performance/http2-vs-http1.1/.
“Async Python Is Not Faster.” Calpaterson.Com, 11 June 2020, https://calpaterson.com/async-python-is-not-faster.html.
Design and Internals — Trio 0.27.0+dev Documentation. https://trio.readthedocs.io/en/latest/design.html#cancel-points-and-schedule-points. Accessed 24 Nov. 2024.